
목차
- 멀티에이전트 디자인 패턴 5가지 — 어떤 구조를 선택할 것인가
- 구축 사례 1 — 코드 리뷰 자동화: Claude Code 서브에이전트
- 구축 사례 2 — CS 자동응답: Coordinator 패턴 아키텍처
- 구축 사례 3 — 데이터 파이프라인: OpenAI Agents SDK 활용
- 멀티에이전트 시스템에서 A2A와 MCP의 역할
- 세 가지 아키텍처 비교 — 패턴·비용·복잡도
- 멀티에이전트 시스템 구축 시 공통 트레이드오프와 주의점
- 다음 단계 — 멀티에이전트 오케스트레이션 심화
💡 관련 상품: 노트북 이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다.
claude --agents '{
"code-reviewer": { "tools": ["Read","Grep","Glob","Bash"], "model": "sonnet" },
"debugger": { "prompt": "Analyze errors, identify root causes." }
}'위 커맨드 한 줄이면 코드 리뷰 전문 에이전트와 디버깅 전문 에이전트가 동시에 뜬다. AI 에이전트 멀티에이전트 시스템 구축 사례를 찾는 이유는 대부분 비슷하다. 하나의 LLM 호출로는 “코드 품질 검사 → 보안 취약점 분석 → 리팩토링 제안”처럼 성격이 다른 작업을 한 번에 처리하기 어렵다. 에이전트를 분리하면 각자 독립된 컨텍스트와 도구 권한으로 작업하고, 결과만 합치면 된다.
세 가지 실무 아키텍처를 다룬다: 코드 리뷰 자동화(Claude Code 서브에이전트), CS 자동응답(Coordinator 패턴), 데이터 파이프라인(OpenAI Agents SDK). 각 사례에 어떤 멀티에이전트 디자인 패턴이 적용되는지, 트레이드오프는 무엇인지 코드와 함께 정리한다.
멀티에이전트 디자인 패턴 5가지 — 어떤 구조를 선택할 것인가
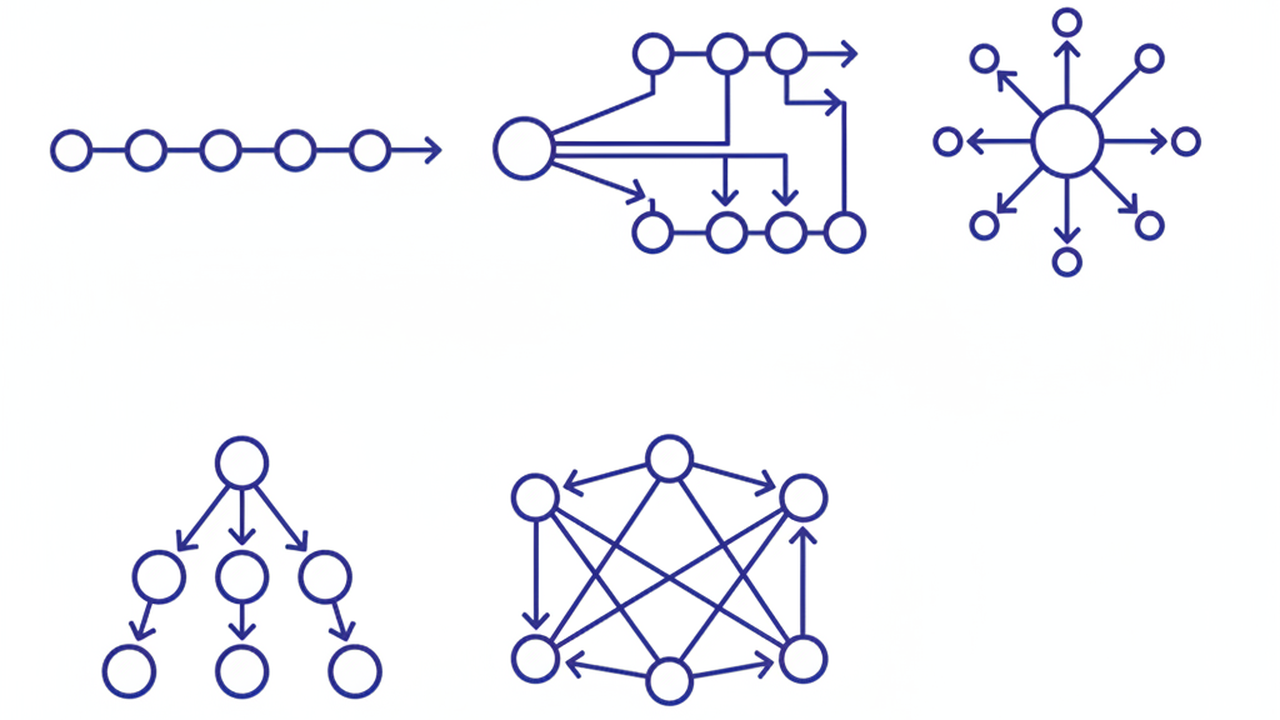
멀티에이전트 시스템을 설계할 때 가장 먼저 결정해야 할 것은 에이전트 간 통신 구조다. Google Cloud 에이전틱 AI 디자인 패턴 가이드에서는 5가지 패턴을 정의한다.
Sequential — 순차 실행
에이전트 A의 출력이 에이전트 B의 입력이 되는 파이프라인 구조다. 데이터 전처리 → 분석 → 보고서 생성처럼 단계가 고정된 워크플로에 적합하다. 구현이 단순하지만, 앞 단계가 느리면 전체 파이프라인이 블로킹된다.
Parallel — 병렬 실행 후 합성
같은 입력을 여러 에이전트에 동시에 넘기고, 결과를 합산하거나 투표로 선택한다. 코드 리뷰에서 보안 검사와 스타일 검사를 동시에 돌리는 경우가 전형적이다.
Coordinator — 중앙 AI가 동적 라우팅
중앙 AI 에이전트가 요청을 분석하고 서브태스크로 분해하여 전문 에이전트에 동적으로 라우팅한다. 유연하지만 모델 호출이 증가하여 단일 에이전트 대비 레이턴시와 운영 비용이 높아진다. CS 자동응답처럼 입력 유형이 다양한 시스템에 적합하다.
Hierarchical Task Decomposition — 계층적 분해
상위 에이전트가 작업을 분해하면 하위 에이전트가 처리하고, 하위 결과를 상위가 종합한다. Coordinator와 비슷하지만, 분해 깊이가 2단계 이상인 점이 다르다.
Swarm — 전체-대-전체 통신
모든 에이전트가 서로 통신하며 반복적으로 개선하는 구조다. 가장 복잡하고 비용이 높으며, 적절한 종료 조건 없이는 비생산적 루프 위험이 있다.
| 패턴 | 레이턴시 | 토큰 소비 | 복잡도 | 적합한 시나리오 |
|---|---|---|---|---|
| Sequential | 높음 (직렬) | 낮음 | 낮음 | 고정 파이프라인, ETL |
| Parallel | 낮음 (병렬) | 중간 | 낮음 | 코드 리뷰, 다중 검증 |
| Coordinator | 중간 | 높음 | 중간 | CS 라우팅, 동적 분기 |
| Hierarchical | 중간~높음 | 높음 | 높음 | 복합 리서치, 대규모 분해 |
| Swarm | 불확정 | 매우 높음 | 매우 높음 | 창작, 반복 개선 |
입력 형태가 고정되어 있으면 Sequential 또는 Parallel 패턴이 적합하다. 입력 유형이 다양하고 실행 경로가 달라져야 하면 Coordinator 또는 Hierarchical 패턴을 선택한다.
구축 사례 1 — 코드 리뷰 자동화: Claude Code 서브에이전트
Claude Code의 서브에이전트는 각자 독립된 컨텍스트 윈도우, 커스텀 시스템 프롬프트, 특정 도구 접근 권한을 갖고 실행된다. 메인 에이전트가 태스크를 위임하면 서브에이전트가 독립적으로 작업을 수행하고 결과만 반환한다. 여러 서브에이전트의 병렬 실행이 가능하며, 읽기 전용 Explore, 계획 수립용 Plan, 범용 general-purpose 등 빌트인 서브에이전트가 포함된다.
코드 리뷰 자동화에 Parallel 패턴을 적용하면 다음과 같은 구조가 된다.
claude --agents '{
"code-reviewer": {
"description": "Expert code reviewer. Use proactively after code changes.",
"prompt": "You are a senior code reviewer. Focus on code quality, security, and best practices.",
"tools": ["Read", "Grep", "Glob", "Bash"],
"model": "sonnet"
},
"debugger": {
"description": "Debugging specialist for errors and test failures.",
"prompt": "You are an expert debugger. Analyze errors, identify root causes, and provide fixes."
}
}'code-reviewer는 Read, Grep, Glob, Bash 도구만 접근 가능하다. debugger는 도구 제한 없이 전체 도구를 사용한다. 두 에이전트가 동시에 실행되면 코드 품질 검사와 에러 분석이 병렬로 처리된다. 이 구조에서 핵심은 도구 권한 분리다. 리뷰어에게 Write 권한을 주지 않으면 코드를 읽기만 하고 수정하지 않는다.
Coordinator 패턴으로 확장하기
서브에이전트가 많아지면 coordinator 패턴으로 특정 서브에이전트만 생성하도록 제한할 수 있다. tools 필드에 Agent(worker, researcher) 형태로 허용 목록을 지정하면, 해당 타입만 생성 가능하다.
---
name: coordinator
description: Coordinates work across specialized agents
tools: Agent(worker, researcher), Read, Bash
---이 설정에서 coordinator는 worker와 researcher 타입만 생성할 수 있다. 서브에이전트는 다른 서브에이전트를 재귀적으로 생성할 수 없으므로, 에이전트 스폰이 무한히 확장되는 문제를 원천 차단한다.
서브에이전트는 단일 세션 내에서 동작한다. 병렬로 동작하며 서로 통신하는 다중 에이전트가 필요하면 agent teams를 사용해야 한다. Agent teams는 별도 세션 간 조율이 가능하다.
구축 사례 2 — CS 자동응답: Coordinator 패턴 아키텍처

CS 자동응답 시스템은 입력 유형이 다양하다. 환불 요청, 배송 조회, 기술 문의, 일반 문의가 모두 같은 채널로 들어온다. 이 경우 Sequential 패턴으로는 대응할 수 없다. Coordinator 패턴이 필요한 전형적인 시나리오다.
Google Cloud 멀티에이전트 레퍼런스 아키텍처에서 코디네이터 에이전트는 Agent2Agent(A2A) 프로토콜로 서브에이전트를 관리하고, MCP(Model Context Protocol)로 도구 접근을 표준화한다. 런타임은 Cloud Run, GKE, Vertex AI Agent Engine 중 선택 가능하다.
CS 시스템 아키텍처 구조
[사용자 입력]
│
▼
┌──────────────┐
│ Coordinator │ ← 요청 분류 + 라우팅
│ Agent │
└──────┬───────┘
│ A2A 프로토콜
┌────┼────┬────────┐
▼ ▼ ▼ ▼
[환불] [배송] [기술문의] [일반]
Agent Agent Agent Agent
│ │ │ │
└────┴──────┴────────┘
│ MCP
▼
[DB / API / CRM]Coordinator Agent가 사용자 메시지를 분석하여 의도를 파악하고, 적절한 전문 에이전트로 라우팅한다. 각 전문 에이전트는 MCP를 통해 DB 조회, API 호출, CRM 업데이트 같은 도구에 접근한다.
보안 요구사항
A2A 프로토콜은 프로덕션 환경에서 HTTPS 필수이며, TLS 1.2+ 지원, OAuth2/OpenID Connect 인증을 HTTP 헤더로 전달하는 보안 요구사항이 명시되어 있다. CS 시스템에서 고객 개인정보를 다루므로 이 보안 레이어는 선택이 아니다.
Google Cloud 레퍼런스 아키텍처에서는 Model Armor로 에이전트 입출력 보안 검사를 수행한다. 고객이 프롬프트 인젝션을 시도하거나, 에이전트가 개인정보를 포함한 응답을 생성하는 경우를 차단하는 용도다.
구축 사례 3 — 데이터 파이프라인: OpenAI Agents SDK 활용
OpenAI Agents SDK는 멀티에이전트 워크플로를 위한 경량 프레임워크로, 에이전트 간 핸드오프(handoff)를 통해 태스크를 위임한다. 주요 기능으로 에이전트 구성(instructions, tools, guardrails, handoffs), 샌드박스 에이전트(파일시스템·명령 실행 환경), 세션 관리, MCP 통합, 100개 이상의 LLM 지원이 포함된다.
데이터 파이프라인에서 Sequential 패턴을 적용하면, 수집 → 정제 → 적재 단계를 각각 독립 에이전트로 분리할 수 있다. 샌드박스 에이전트를 사용하면 파일시스템과 명령 실행 환경이 격리되어, 데이터 정제 스크립트가 호스트 시스템에 영향을 주지 않는다.
from agents import Runner
from agents.sandbox import Manifest, SandboxAgent, SandboxRunConfig
from agents.sandbox.entries import GitRepo
from agents.sandbox.sandboxes import UnixLocalSandboxClient
agent = SandboxAgent(
name="Workspace Assistant",
instructions="Inspect the sandbox workspace before answering.",
default_manifest=Manifest(
entries={
"repo": GitRepo(repo="openai/openai-agents-python", ref="main"),
}
),
)
result = Runner.run_sync(
agent,
"Inspect the repo README and summarize what this project does.",
run_config=RunConfig(sandbox=SandboxRunConfig(client=UnixLocalSandboxClient())),
)이 코드에서 SandboxAgent는 Git 레포를 샌드박스 워크스페이스에 클론하고, 격리된 환경에서 파일을 분석한다. UnixLocalSandboxClient는 로컬 Unix 환경에서 샌드박스를 실행한다. 데이터 파이프라인에서는 이 패턴을 확장하여 수집 에이전트가 외부 API를 호출해 데이터를 받고, 정제 에이전트가 샌드박스 내에서 전처리 스크립트를 실행하는 구조로 구성한다.
핸드오프 기반 태스크 위임
OpenAI Agents SDK의 핵심 개념은 핸드오프다. 에이전트 A가 작업을 완료하면, 다음 단계를 담당하는 에이전트 B에 컨텍스트와 함께 제어권을 넘긴다. Sequential 패턴의 자연스러운 구현이다. 핸드오프 시점에 guardrails를 설정하면, 다음 에이전트에 전달되는 데이터가 스키마에 맞는지 검증할 수 있다.
데이터 파이프라인에서 에이전트를 분리하는 실질적 이점은 세 가지다.
- 장애 격리 — 정제 에이전트가 실패해도 수집 에이전트의 결과물은 보존된다
- 독립 스케일링 — 수집이 병목이면 수집 에이전트만 복제할 수 있다
- 모델 분리 — 단순 ETL에는 경량 모델, 비정형 데이터 해석에는 고성능 모델을 배정한다
위 코드는 OpenAI Agents SDK GitHub 리포지토리 README에서 확인된 예제다. platform.openai.com 공식 문서가 403으로 접근 불가한 상태여서 Agents SDK 공식 가이드의 상세 내용은 별도로 확인되지 않았다.
멀티에이전트 시스템에서 A2A와 MCP의 역할
AI 에이전트 멀티에이전트 시스템 구축 사례를 본격적으로 프로덕션에 올리면, 에이전트 간 통신 표준이 필수가 된다. 서로 다른 프레임워크(Claude Code, OpenAI Agents SDK, Google ADK)로 만든 에이전트를 하나의 시스템에서 운영하려면 공통 프로토콜이 필요하다.
A2A(Agent2Agent) 프로토콜
A2A 프로토콜은 서로 다른 프로그래밍 언어와 런타임의 에이전트 간 상호운용성을 제공한다. Python으로 작성된 데이터 정제 에이전트와 TypeScript로 작성된 알림 에이전트가 같은 파이프라인에서 동작해야 할 때, A2A가 이 간극을 메운다.
프로덕션 환경에서의 보안 요구사항은 다음과 같다.
- HTTPS 필수
- TLS 1.2+ 지원
- OAuth2/OpenID Connect 인증을 HTTP 헤더로 전달
A2A 프로토콜의 구체적인 구현 코드 예제는 공식 문서에 아직 명시되어 있지 않다. 현재는 프로토콜 명세와 레퍼런스 아키텍처 수준의 가이드만 제공되는 상태이므로, 실제 구현 시 프로토콜 명세를 직접 참조해야 한다.
MCP(Model Context Protocol)
MCP는 에이전트가 외부 도구에 접근하는 방식을 표준화한다. Google Cloud 멀티에이전트 레퍼런스 아키텍처에서 코디네이터 에이전트는 A2A로 서브에이전트를 관리하고, MCP로 도구 접근을 표준화하는 이중 프로토콜 구조를 취한다.
| 프로토콜 | 역할 | 통신 대상 |
|---|---|---|
| A2A | 에이전트 ↔ 에이전트 | 서로 다른 런타임의 에이전트 간 |
| MCP | 에이전트 → 도구 | DB, API, 파일시스템 등 외부 리소스 |
두 프로토콜의 역할이 다르다. A2A는 에이전트 간 수평 통신, MCP는 에이전트에서 도구로의 수직 접근이다. 멀티에이전트 시스템에서 A2A만 쓰면 도구 접근이 에이전트마다 제각각이 되고, MCP만 쓰면 에이전트 간 라우팅을 직접 구현해야 한다.
세 가지 아키텍처 비교 — 패턴·비용·복잡도
앞서 다룬 세 가지 구축 사례를 패턴·비용·복잡도 기준으로 비교한다.
| 항목 | 코드 리뷰 (Claude Code) | CS 자동응답 (Coordinator) | 데이터 파이프라인 (OpenAI SDK) |
|---|---|---|---|
| 디자인 패턴 | Parallel + Coordinator | Coordinator | Sequential |
| 에이전트 수 | 2~4 | 4~6 | 2~3 |
| 모델 호출 횟수/건 | 2~4회 | 2~3회 | 2~3회 |
| 통신 방식 | 단일 세션 내 | A2A + MCP | 핸드오프 |
| 주요 트레이드오프 | 병렬 실행 시 토큰 소비 증가 | 분류 레이어 추가 비용 | 순차 실행 레이턴시 |
| 장애 격리 | 서브에이전트 독립 | 에이전트별 독립 | 단계별 독립 |
세 사례 모두 에이전트 분리의 핵심 이점은 동일하다. 각 에이전트가 독립된 컨텍스트와 도구 권한을 가지므로, 한 에이전트의 실패가 전체 시스템을 중단시키지 않는다. 차이는 통신 구조와 오케스트레이션 복잡도에 있다.
Google Cloud 공식 문서는 7개의 멀티에이전트 배포 예제를 제공한다. 금융 어드바이저(주식 거래 추천), 리서치 어시스턴트(계획-수집-평가), 보험 에이전트(가입·청구 처리), 검색 최적화기, 데이터 분석기, 웹마케팅 에이전트, Airbnb 플래너가 포함되며, 위 세 사례 외에도 멀티에이전트 적용 가능 영역이 넓다는 점을 보여준다.
패턴 선택 기준 정리
단순 규칙으로 정리하면 이렇다.
- 입력 형태가 고정 → Sequential 또는 Parallel
- 입력 유형이 다양하고 분기 필요 → Coordinator
- 작업 분해 깊이가 2단계 이상 → Hierarchical
- 에이전트 간 상호 피드백 필요 → Swarm (비용 주의)
- 생성 결과 검증 필요 → Review & Critique 결합
- 고위험 결정 → Human-in-the-Loop 결합
실무에서는 단일 패턴보다 패턴 조합이 일반적이다. 코드 리뷰 사례처럼 Parallel + Coordinator를 섞거나, 데이터 파이프라인에 Review & Critique를 추가하여 적재 전 데이터 품질을 검증하는 구조가 현실적이다.
멀티에이전트 시스템 구축 시 공통 트레이드오프와 주의점
실제 기업 프로덕션 멀티에이전트 배포 사례의 정량적 성과 지표는 공식 문서에 없다. 따라서 아래 트레이드오프는 아키텍처 설계 수준의 분석이다.
비용 증가: 에이전트 수가 늘어나면 모델 호출 횟수가 비례하여 증가한다. Coordinator 패턴은 분류 + 처리로 최소 2회 호출이며, Swarm은 반복 횟수에 비례하여 호출이 급증한다. 토큰 단가가 낮은 모델을 분류기에 배정하고, 고성능 모델은 최종 처리에만 사용하는 모델 티어링 전략이 필요하다.
레이턴시: Parallel 패턴은 가장 느린 에이전트의 응답 시간이 전체 레이턴시를 결정한다. Sequential 패턴은 모든 에이전트의 응답 시간 합이 전체 레이턴시다. 실시간 응답이 필요한 CS 시스템에서는 각 에이전트의 타임아웃을 개별 설정해야 한다.
디버깅 복잡도: 에이전트가 3개 이상이면 어떤 에이전트가 잘못된 결과를 냈는지 추적하기 어렵다. 각 에이전트의 입출력을 로깅하고, 트레이싱 ID를 요청 단위로 부여하는 observability 설계가 선행되어야 한다.
Google Cloud 환경이라면 Cloud Run(서버리스, 소규모), GKE(컨테이너, 대규모), Vertex AI Agent Engine(관리형) 중 트래픽 규모와 운영 역량에 맞게 선택한다. 각 옵션의 오토스케일링 특성이 다르므로 에이전트 응답 시간 SLA에 따라 결정한다.
다음 단계 — 멀티에이전트 오케스트레이션 심화
AI 에이전트 멀티에이전트 시스템 구축 사례의 기본 구조를 잡았다면, 다음으로 깊이 들어갈 영역이 세 가지 있다. 첫째는 MCP 서버를 직접 구축하여 에이전트가 사내 DB와 API에 표준화된 방식으로 접근하도록 만드는 것이다. MCP 서버 하나를 만들면 Claude Code 서브에이전트든 OpenAI Agents SDK든 같은 도구 인터페이스로 연결할 수 있다.
둘째는 에이전트 간 핸드오프 시 컨텍스트 손실을 최소화하는 세션 관리 설계다. 에이전트가 많아질수록 이전 에이전트의 중간 결과물이 다음 에이전트에 온전히 전달되는지 검증하는 계층이 필요하다. 셋째는 에이전트 실행 비용을 모니터링하고 토큰 사용량을 에이전트별로 추적하는 observability 파이프라인 구축이다. 멀티에이전트 오케스트레이션 패턴과 AI 에이전트 디자인 패턴에 대한 이해가 깊어지면, 단일 에이전트로는 불가능한 복잡한 워크플로를 안정적으로 운영할 수 있다.